Toolkit for real-world performance evaluation of medical grade deep learning models

Motivation
Research studies from Dr. Shah’s lab have described several deep learning methods and models to assist clinical decision-making using medical images. Reliable segmentation of cells or tissues from medical images continues to remain a critical need for generalizable deep learning. Random initialization or transfer of model weights from natural-world images, gradient-based heatmaps, and manifold learning have been used to provide insights for image classification tasks. An automated workflow based on statistical reasoning that achieves reproducible medical image segmentation is lacking. The toolkit reported in this study led by Dr. Shah and published in Cell Reports Methods identifies training and validation data splits, automates the selection of medical images segmented with high accuracy, and describes an algorithm for visualization and computation of real-world performance of deep-learning models.
Technical summary
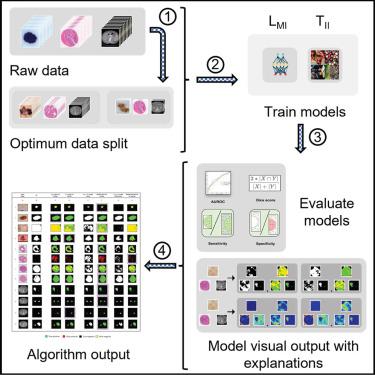
Generalizability of deep-learning (DL) model performance is not well understood and uses anecdotal assumptions for increasing training data to improve segmentation of medical images. We report statistical methods for visual interpretation of DL models trained using ImageNet initialization with natural-world (TII) and supervised learning with medical images (LMI) for binary segmentation of skin cancer, prostate tumors, and kidneys. An algorithm for computation of Dice scores from union and intersections of individual output masks was developed for synergistic segmentation by TII and LMI models. Stress testing with non-Gaussian distributions of infrequent clinical labels and images showed that sparsity of natural-world and domain medical images can counterintuitively reduce type I and type II errors of DL models. A toolkit of 30 TII and LMI models, code, and visual outputs of 59,967 images is shared to identify the target and non-target medical image pixels and clinical labels to explain the performance of DL models.
FAQ
-
What is the value proposition of this work?
This study reports a process and methods for generalizing deep learning (DL) image segmentation using natural-world (TII) models (trained with supervised TL with ImageNet initialization and fine-tuned on medical images) or learning with medical images (LMI) models (trained with supervised learning trained natively on only medical images) for the binary segmentation of tumors and organs. Statistical estimation and visual explanation of the training data and DL model outputs for segmentation of three unique medical image subtypes of microscopic digital histopathology, RGB skin dermatology and Computed Tomography widely used for computational medicine research and clinical decsion-making were set as targets. Key goal was to support researchers working with small numbers of images and labels in multiple fields to train high-performance DL models and provide resources for their interpretability.
-
What were the key findings from this work?
The study reported (1) detailed validation of a process for maximizing available clinical labels and medical images for synergistic use of TII and LMI models; (2) a description of parametric and non-parametric statistical methods to test significance of data distributions; (3) model performance estimation by using the area under the receiver operating curve (AUROC), Dice (F1) score, sensitivity, and specificity of segmentation of target features; (4) estimation and identification of the least numbers and types of individual images and available clinical labels for improvement of model performance; (5) Grad-CAM and uniform manifold approximation and projection (UMAP)-based visualization and interpretation of LMI and TII DL models; and (6) an algorithm that automates the comparison of Dice scores by multiple DL models to compute the highest possible accuracy of segmentation of medical image pixels contributing to type I and type II errors
-
What are the main outcomes and the meaning of this work for deep learning research and clinical applications?
The DL and statistical methods communicated in this study and findings derived from them can be used for selecting the best training and validation data splits, using the least numbers of images required for high-performance segmentation, and automated selection of best-performing models and correctly segmented images. The Dice score computation algorithm also automated screening for robust segmentation performance from multiple models. The approach described in this study may also alleviate under specification and stress testing challenges precluding real-world deployment of DL models when tested with adversarial or previously unseen data.
The methods, code, and models from this study can be used as starting points for custom applications and to benchmark the performance of datasets and explainable DL models of choice. The open-access GitHub repository hosting (1) 30 fully trained and validated DL models (15 models each for LMI and TII translating to 10 models for each of the three image modalities), (2) Grad-CAM results and the associated software code and performance estimation from more than 10,000 test images, and (3) a separate statistical analysis package for calculating the AUROC, Dice score, and sensitivity/specificity performance of DL models will be a valuable resource for biomedical and computer science researchers.
-
What are the next steps?
The United States Food and Drug Administration is in the process of making key determinations for regulatory strategies provided by deep learning for health care decisions to treat, diagnose, drive, support or inform clinical management. By describing explainable algorithms and quantitative methods that can consistently, rapidly, and accurately evaluate real-world performance of deep learning models, this study communicates a detailed method and process that may be useful to generate evidence for clinical and regulatory authentications. Dr. Shah has ongoing collaborations with regulatory agencies, academic hospitals and foundations for prospective validation and randomized clinical trials.
-
What are the limitations and future growth area of this research?
Although benchmarked datasets and widely used DNN architectures and models were used, the findings from this study were optimized for the medical images, clinical labels, and DNN specifically used for this research. Skin cancer and prostate tumor regions annotated by pathologists can be coarse, contain non-relevant tissue and skin, which can increase disagreements with DL segmentation performance. Additional fine-grained clinical image annotation tools and labeled images are being collected.
Citation
A deep-learning toolkit for visualization and interpretation of segmented medical images,
Cell Reports Methods, Volume 1, Issue 7, 2021. https://doi.org/10.1016/j.crmeth.2021.100107
Contributors and coauthors
Sambuddha Ghosal: Postdoc associate
Pratik Shah^: Principal investigator
^ Senior and corresponding author.
